Solving the Wizard Problem
I've never been happy with any wizard implementation I've ever done. When I think back in time through the sites and apps I've worked on, there are parts I'm proud of. But when I think of the wizard implementations across past projects...each one's just sitting there, taunting me. An unsanded corner in an otherwise smooth piece.
However, recently, I finally feel like I've cracked this problem. If I were to go back and refactor or implement again, I'd know how to do it better. I could implement it in a way that wouldn't bug me. It's this approach I'd like to share with you here.
This approach changed the amount of time and manpower it took to ship from ~6 weeks/1 team at a time to ~(time for new pieces of functionality)/n teams in parallel. Complete reuse of existing work, all sorts of flexibility to accomodate frequent change requests, and better yet - a step towards self-service (aka not needing devs to commit code to ship things). It provided an order of magnitude improvement.
Before I get ahead of myself, the "wizard problem" is my label for complex, multi-step forms. Unfortunately, I'm not talking about literal wizards and wizardry. While this topic might seem esoteric, in reality, these kinds of interactions are all over the place.
Naughty, Naughty Wizards #
They're often introduced into a codebase, innocuously, in an area where not doing a wizard would be "unimaginable," like:
- signup flows
- complex business processes (you ever filed taxes online?)
You'll notice these are some fairly business-critical areas. However, once the pattern's been established, they tend to shed their skin and creep into other places and/or grow in complexity. Sometimes implementation is reused, sometimes it diverges. Feedback forms, variability in signup, conditionally branching flows, wizard-versions of other large forms, etc. Interestingly, I've also noticed every time I witness someone less-technical start fuming at a computer when I look at their screen - you guessed it! - it's a wizard (which either isn't working, or didn't save their progress).
One final meta-comment-turned section before I get into the meat and bones of this. I don't know whether this approach would technically classify as "architecture" or not. However, because I'm giving advice on how to build software, I'm going to address this in a slightly different way than, say, a technical breakdown I might give to someone new joining the project. I don't think most architectural guidance on the internet is as good as it could be because it doesn't leave enough space or guidance to play nicely into applying to your situation. It tends to fall into "always do x," "we did y," or "never do z."
If you're a dev at BigCo, or a more solo dev on a small remote team, this post's for you. This approach has resulted in systems safely/quickly modifiable by people with very little exposure to it beforehand in both contexts.
Preparing for the Wizard Duel #
What I'm going to equip you with by the end of this blog post isn't how to "implement wizards" - that's not good enough. What you're going to get here is:
- An understanding of the story and the context the approaches I'll walk through emerged to address,
- Awareness of the right dimensions to pay attention to, and
- A set of questions to answer that'll help you know when and why it'd make sense to choose (or not) different amounts of work.
Here's my recommendation: This approach could work in the context of any modern SPA (single-page application) and is agnostic to React vs Vue vs Web Components, etc. Although I haven't implemented this in a server-rendered context yet (like Rails, Django, or Laravel) I still feel good recommending it there, too.
I'll give specific recommendations from the pov of an SPA since that's what I actually helped implement, and a server-rendered approach would simply cut pieces of the implementation out. This starts abstract and ends concrete. I'll be laying bare the essential pieces in what eventually gets to fairly fine-grained detail so you can interact with this post to move your thinking way ahead. I will, however, have to sometimes include semi-proprietary pieces of info if it adds congruence to the system.
There's no one right way to tackle these interactions. I'm sure there are better ways (deep in some cms, or some large enterprise somewhere...) But what I can say is, this way makes me feel deeply content and like I'm doing a responsible job. It's pretty great. I want you to feel that way, too.
This post is/will be long and somewhat exhaustive.
A Tale of "Could you make sure people can't set the thru-date once a campaign is active, except sometimes?" #
At my place (Maritz), we have a pretty beastly domain concept which both ties most of our other domain concepts together (in a neat little package! 😊) and also serves as the major transition pathway between the "administrative" area of our app, and the "true-end-user" area of our app.
This particular domain concept has an interesting property. There are many versions of it, most of which have yet to come into existence. You can think of it like chocolate bars - some have nougat, some have nuts, and some have caramel. They're all fundamentally a chocolate bar, but each contains material differences.
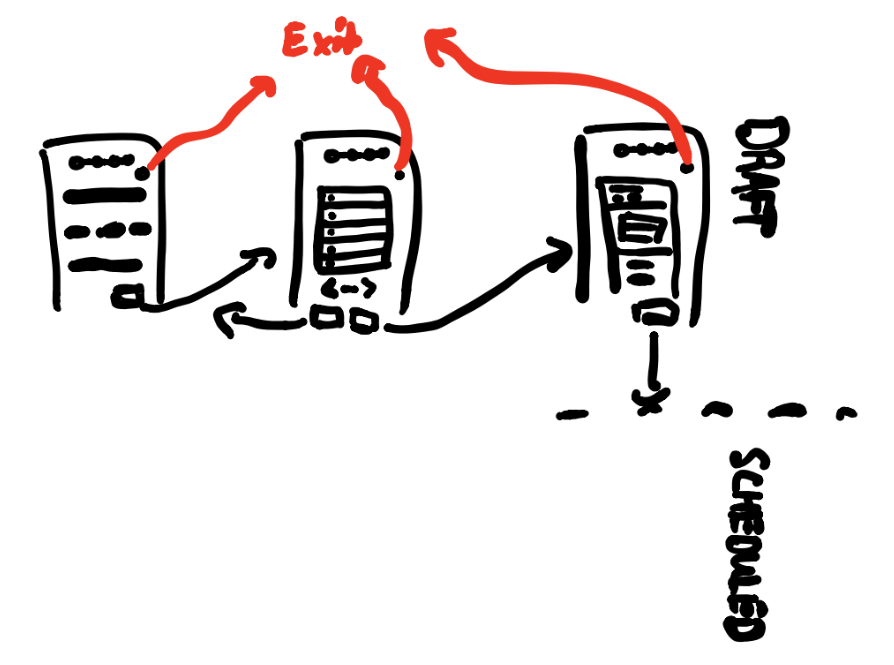
Let's unpack this picture. Some of the steps have multiple inputs. Some are dedicated to filtering, searching and sorting through data (often in tables) to find and save the particular selection you're after. Finally, at the end, we have all the contents of all the forms from the previous steps pulled together into a non-editable state so a user can review what they've done. Notice: you might need data on one step (the possible selections for you to choose from) you don't need on any other. You also need two views of your data: editing, and viewing.
All of the steps have "steppers," or some kind of affordance that communicates where a user is, and how far they have left to go. Potentially, this is even interactive (more on this later). All of the steps also have "wizard buttons," like "next" and "previous" and of course "submit" (a classic). They also all have means of exiting the flow and navigating back to the root page.
If you only have one flow for one domain concept, and there are no other layers of variance you know you need now, congratulations. Hardcode it. You're done.
However, if you're not sure, or you think you might wanna reuse pieces of functionality you've built here in other ways...
Identify your Layers of Variance #
By "layer of variance" I mean a dimension which contains some discrete set of members with a forecastable growth rate of some type. You figure this out if you can get a reasonably confident from-the-gut statement from your pm (project manager), po (product owner), your favorite ux designer or yourself on "will we have more of these?" or "will we have different kinds of these?"
There are three major layers most implementations will need to grapple with we'll talk about off the bat.
Variance of Kind
In our case, we had and will definitely have more of different sorts of campaigns.
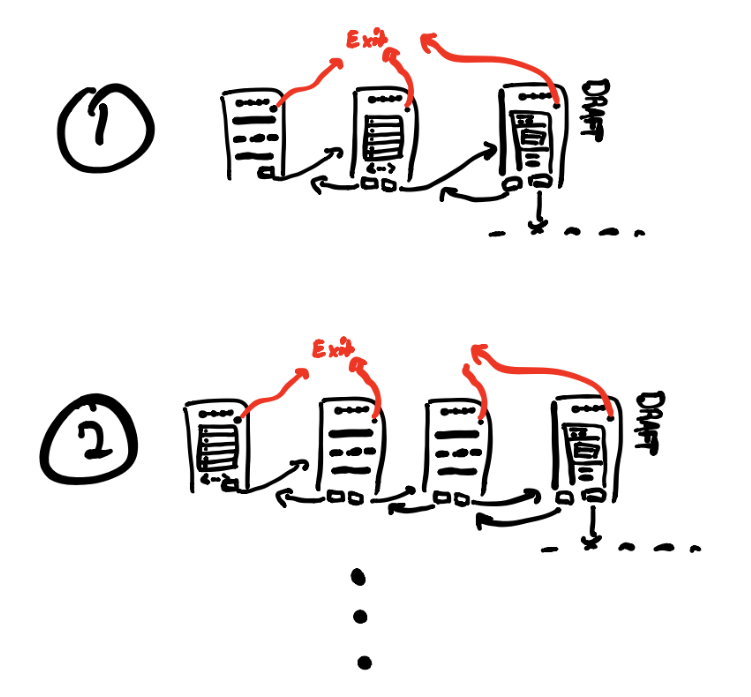
If your domain concept encapsulates different sub-types of itself, chances are you're going to want to reuse pieces of one type on other types current and future. This will have impact on what data structure you choose to accomodate change nicely, and consequently how much investment you make into it.
Variance of Phase
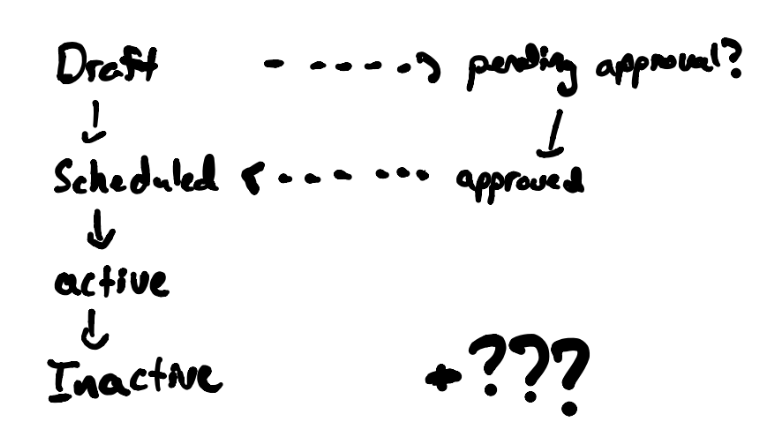
Usually (but not always) there's some kind of state machine hiding inside domain concepts or interactions complex enough to warrant a wizard. In our case, our campaign could transition through various phases (which we termed, it's "lifecycle"). We also had the spectre of approvals looming in the future. If you have any kind of design that's not a user getting to the end and submitting all at once, you minimially have at least two phases ("draft" and "published").
Each phase had impact on what information should be available in what order, and in what state (editable, view-only).
Variance of Circumstance
Sometimes you have variance indirectly related to your domain concept which still has impact on how to implement for it.
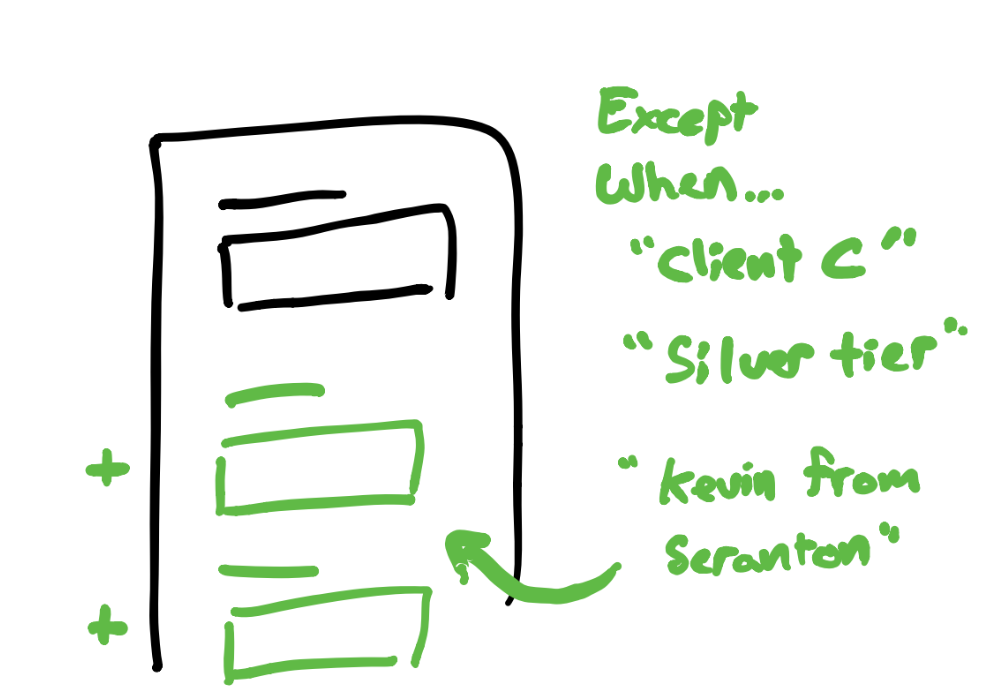
We had plenty of this, taken care of primarily through feature flagging (via LaunchDarkly). If you don't already use feature flagging, then supporting this will have impact somewhere in your data structure for the wizard.
Identify Your Key Design Goals & Addressment Mechanisms #
(I know addressment isn't a real word, but I typed it, and I liked it, so it's here to stay). One of the key needs of any wizard interaction is, from the pov of a user, not losing progress. Two of the ways you can address this are through proper exit dialogs or progressive save. Initially, we went with progressive save.
Next - power user? Sometimes-user? Single-use user? If you're building for power users, chances are you're going to want to make tabbing through different affordances super friendly. The ease of interaction in the tail is more important than the ease of acquiring familiarity. On the other end of this dimension, you have single-use users where they'll go through it once (think signup). You're going to make choices about spacing, sequencing and labels based around what you think is most likely to help people complete the wizard. This edges into UX territory, but
Finally - a11y (accessibility) - is this a one-off page for one person a little ways over? Or is this intended for full consumer use? Get clarity on this up-front.
Designing and Placing Your Key Data Structure #
Here's the key thing I missed on all my early attempts at wizarding, and what I chipped away at until it clicked.
Initially I thought of the only "data" as the information collected by the wizard. But...the name and sequence of your steps and the contents on each step are all data, too. To drive this point home, I'll walk through what we didn't do. Initially, we built under the assumption 1) there would be one flow of steps, 2) steps would be the same across all phases, and 3) it made sense to account for variance inside the steps.
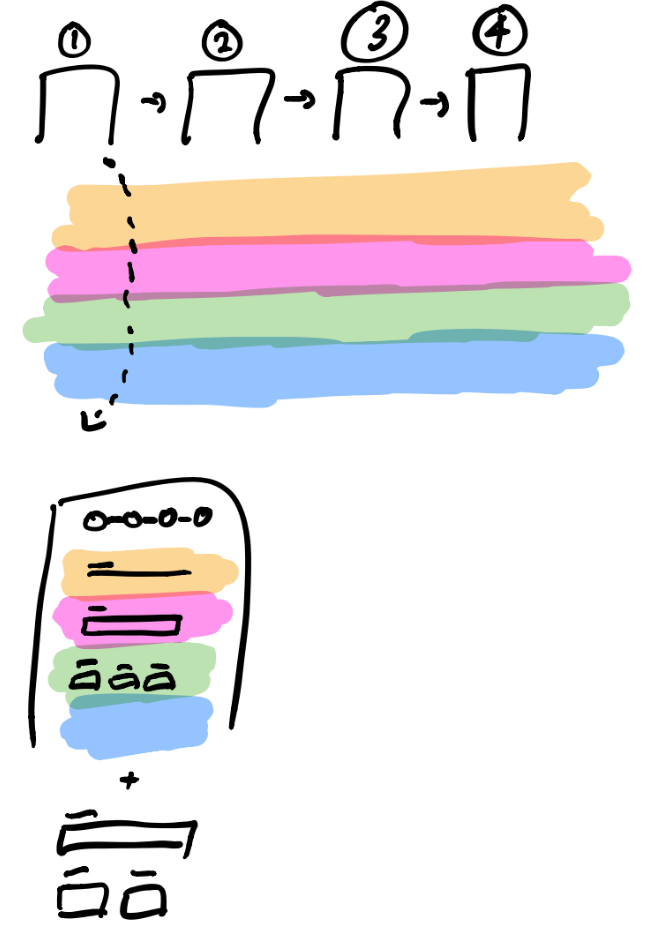
You know what happens then? You accrue all the layers of variance inside your steps. You start ending up with a lot of if's in them, gradually making the system harder to comprehend and maintain over time.
Each layer of variance you need to accomodate is potentially a layer of nesting in your data structure. We'll store them in the "wizard map." This map isn't in the sense of a cs way but more of a "tells where things are located" kind of way. It's a data structure that contains the richness of the wizard inside of it for both computers and people.
It is much easier to update a data structure than updating an implementation of an implicit data structure. It's also much easier to accomodate error-correction ("oh woops, we need to make sure our steps evaluate feature flags and do it every time") in a "typed declarative data structure" -> "capability" kind of flow than not.
We have three layers of variance here. Kind, phase, and circumstance. You could put these all in one massive file, but here's how I'd recommend laying them out:
- Different kinds get their own files (or some other means of encapsulation if it floats your boat)
- Then by phases, then by steps
- Circumstantial variance data is reflected and accounted for inside individual steps
const wizardMap = {
statuses: {
draft: {
/* steps */
},
scheduled: {
/* steps */
}
/* ... */
}
};Now when I say steps, I mean information about what the step is and what's inside it.
const steps = [
{
name: "description",
parts: [
/* ... */
]
},
{
name: "budget",
parts: [
/* ... */
]
},
{
name: "review",
parts: [
/* ... */
]
}
];Finally, inside each step are the "parts" - or things which show up on the page. Designing parts is it's own section, so I'll skip that for now.
The one consideration here is if/when you get branching step structures. You could accomplish this via two means:
- Embedding the variance inside the steps themselves, and adding some sort of conditional control-flow there via pulling in different parts, or
- Enhance the data structure you store steps inside to be a graph.
I've not had to do this yet. If I did, here's my first take. Instead of storing steps as a list, I'd store them in a graph and figure out some way to deal with conditionals. In particular, I'd adopt a syntax from Statecharts/XState to accomplish this. I'll walk through a minimal case. If you're in a situation where you can direct what these are, you can use id to identify steps. If this will be system- or user-generated, probably better to assign unique id's to each in case people would name two steps "description." Here, I use "id".
- Each
nodewould be data representing a step. - Each
edgecontains data needed to help construct what the pathway of steps should be. - Each
conditionis a function that consumes whatever context it needs to make a decision.
From here, maintaining a piece of currentStep + information contained in this data structure should be all you need to represent any set of wizard flows.
const steps = {
nodes: [
{
id: "description",
name: "description",
parts: [
/* ... */
]
},
{
id: "budget",
name: "budget",
parts: [
/* ... */
]
},
{
id: "review",
name: "review",
parts: [
/* ... */
]
}
],
edges: [
[
{ from: "description", to: "budget", cond: "needsBudget" },
{ from: "description", to: "review" }
],
[
{ from: "budget", to: "review" }
],
[
{ from: "review" }
]
],
conditions: {
needsBudget: (context) => !!context.steps["description"].form.hasAwards
}
};The key here is in the edge data structure. Each member should contain, in sequential order, all the states it could exist in. The keys to and cond are optional. Here, it's easy to glean that this wizard will be 2 or 3 steps long, depending on whether someone checked "hasAwards" on the first step. Storing conditions behind keys (needsBudget) allows for reuse of common conditions across different flows and places.
If you need dynamically generated flows from here, this approach doesn't deal with parallel pathways efficiently. You're probably going to want similar data shaping, but assume you'll have a layer that can take the data, current state, and form it into a full-fledged graph you can ask questions of.
In fact, storing things in a statechart-like structure is so ridiculously useful, I actually recommend you use it (or some version of it) as your substrate upon which the wizard implementation is actually built. Before we dive into the specific design for this, there's one final consideration here.
API Design #
The layers of variance you've identified also apply inside your API design. You're going to start with a singular domain concept, like the canonical campaign.
You'll want to design it so:
- Any set of pieces of data of a domain concept can get updated at a time
- Validations only apply to the pieces of data being modified, and their dependents (so you don't care what's on any step or how they're ordered)
- Whole-object validations only apply at phase transitions, and the full set of validations needs to have already been run by the time the user gets there (meaning the design of your wizard flow should accomplish this)
For example, a campaign might include:
namedescriptionfromDatethruDatehasAwardsbudgetId
Beyond validations per-property, the dependencies/validations here are:
thruDatecan't be beforefromDatebudgetIdis required ifhasAwardsis true
I should be able to write:
thruDateonly iffromDatehas been setbudgetIdonly ifhasAwardsis true
But otherwise, if I send over any of the other pieces of data, I should be able to flexibly shape requests to include any of them.
By the time I reach the review step, all pieces of data should be satisfactorily built out (but if not - the wizard should still error out and communicate to the user appropriately what they need to do still).
These approaches need be nested in a "strategy-" like approach, where different validation strategies apply to requests which identify as different kinds of campaigns.
Next, you also have the data structure of your wizard itself (not just the data your wizard collects). I recommend you leave this as source code hardcoded on your front-end for a while, then eventually extracting it into a database later. This way, the UI can rapidly iterate & it's in source control. Only after you've let it survive the stresses of true user interaction and demonstrate it's fitness/stability do you invest the time and work to extract it into a backend. (It's at this point you could start thinking about providing an editor on top of this data structure to let users put together their own wizard flows of existing parts).
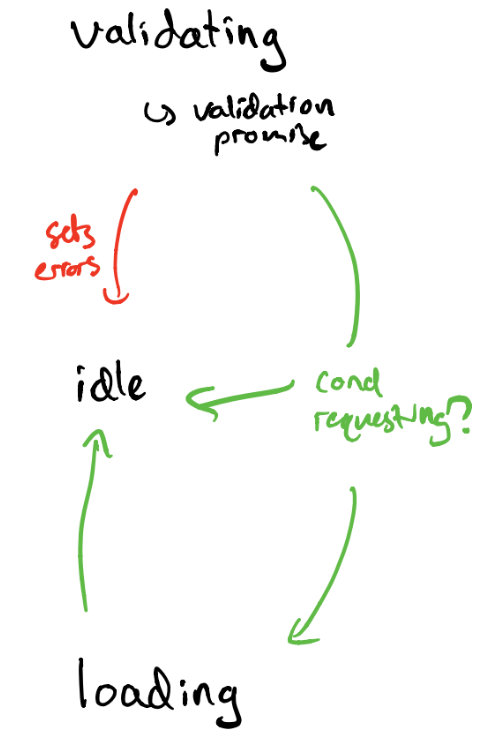
State Design (just before the view layer) #
You've figured out what kinds of changes you're going to need to deal with. You've thought through your domain, and it's time to get something on the page. Here's where we get down'n'dirty. To tackle this problem, I leaned on the StateCharts specification and a JS-based implementation named XState.
This is a really cool and mature approach to designing systems that historically hasn't crashed into web application development shores (although that's hopefully shifting!). When I need to refactor a hairy piece of code, or implement a truly complicated interaction, these are the tools I lean on because they've cracked problems I haven't been able to any other way.
For those of you who don't want to dive down the rabbit holes linked above, here's a brief explanation.
Let's see if I can do this in one run-on sentence: A statechart is like a finite state machine where you recursively nest more finite state machines to represent all the possible states of your system you know you know ahead of time (the finite state), and an extra area (think a js object you can put whatever you want inside) where you can store anything else you'd need, or that'd be infeasible to represent as a graph, like user input. (This other portion is called the "extended state".)
XState stores the notion of a "machine" as a configuration. From there, you can "invoke" (aka instantiate) machines as services. A running service, if it needs, can instantiate more machines into services as children. The only way to interact with a service is to send an event, which can potentially cause a transition.
Those of you more widely read will probably recognize I'm talking about building this UI in the actor model (simplified of most of the distributed systems problems 'cuz we're running in a browser). Some of you might even glean, this design trends towards the functional core, imperative shell approach (which you'll see also referred to in more buzzwordy terms the "integration operation segregation principle", but I prefer plain english to most any other phrasing when possible).
All right. We'll be dealing with all the layers of variance discussed thus far. Here's what this looks like in practice:
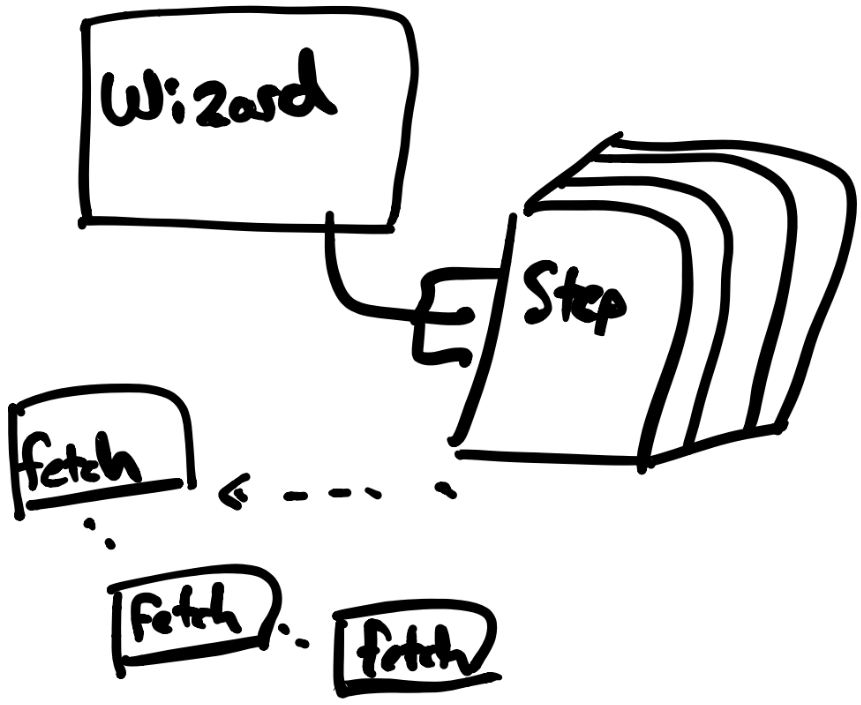
The Wizard
- Contains "server-truth", or last-known status of your domain object as the server sees it
- Responsible for determining 1) which wizard map to behave around, 2) which step, 3) error states
- Responsible for server communication
- Responsible for spinning up and maintaining the service for each step
Each Step is responsible for:
- understanding what parts need to go on the page, and what supporting data helps them
- tracking the state of the "form" (which is composed of the parts on that page)
- managing part-specific network requests
- tracking local state the step on the page needs to track (pagination, toggles, etc)
- running client-side validations, and interpreting validations
We'll come back to this. There are some important principles to have in mind while you're developing yours, but let's look through the design of the system.
StateChart Design #
Wizard
Nodes:
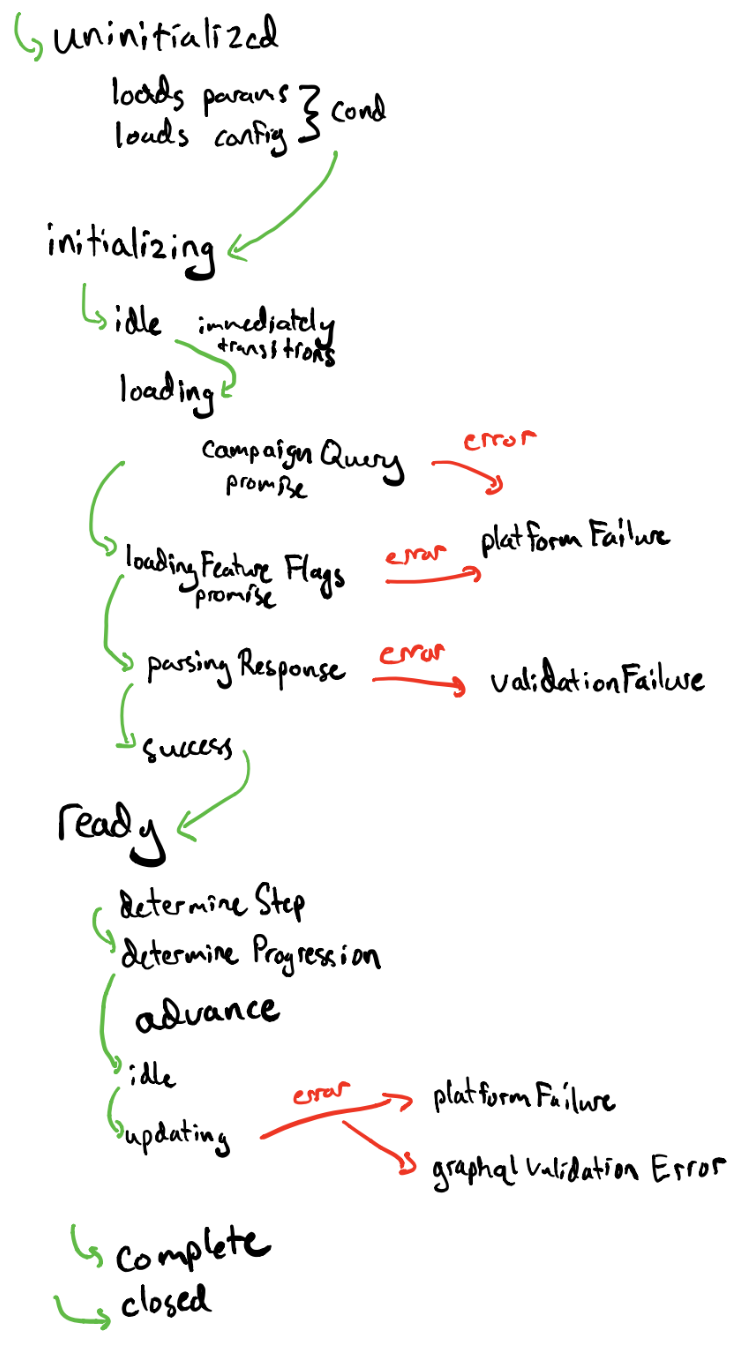
Events:
- SetParams (from url)
- SetWizardMap (consumes info provided by url)
- UpdateConfig (info needed for making api requests from outer application, sourced from redux in this case)
- CampaignQuerySuccess
- CampaignQueryPlatformError
- CampaignMutationSuccess
- CampaignMutationPlatformError
- StepValid (steps tell wizard where they're at)
- StepInvalid
Context:
- params
- slug
- campaign type
- id
- config
- features
- errors
- map
- campaign
- queryResponse
- mutationResponse
- steps (stores references to all step services; populates upon successful return of campaign query)
- location
- hasPreviousStep
- hasNextStep
- currentStepIndex
- furthestAccessibleStepIndex
- currentStepSlug
- attemptedSlug
Step
Nodes:
Events:
- Input (individual participating form parts)
- Submit
- ConfigUpdated
- CampaignUpdated
- UseQuery (kicks off a fetch request for specific graphql doc w/ associated params from step's local state, like what page or filters)
- CancelQueries (ignores responses from existing query promises underway)
- FetchRequest (sent to fetchMachine to kick it off)
- FetchEventLoading (FetchEvent's are returned by an instantiated fetch service)
- FetchEventSuccess
- FetchEventFailure
- UpdateDisplayState (local state to step)
Context:
- config
- definition (relevant step definition from map)
- form (all form data)
- supplemental (additional data requestable via declaring on map; doesn't participate in requests)
- validForm
- queries (stores results of step-specific requests)
- errors
- displayState (state local to the step, lives only as long as step is displayed on the page)
- validationSchema (holds info needed to validate shape of step at this particular time)
Design of Parts #
There's one piece of the map's data model I've neglected until this point. Parts, or the individual elements that make up the content of different steps on the page. There are fundamentally two kinds of parts, those that edit data and those that display data. We conventionalized this by saying ${domainConcept}-editing or ${domainConcept}-viewing
- component - key we can use to retrieve correct functional component we'll call to render this concern. ex:
budget-editing - name - the
nameof the property inside form this part will update. ex:budgetId - label - the label applied to the part. (these change a lot depending on ux and we'll need to i18n them soon)
- queries - the keys of corresponding graphql docs this step might use. ex:
budgetSelectionsQuery - validations - a serializable list of validations this step will use to determine it's own validity.
- supplementalFields - extra info this part requests from the greater context. ex:
budget, which we use to show a card of the selected budget - attributes - it's useful to be able to set attributes directly on our components.
- inputType - the domain object we interact with is large and spans multiple backend systems. we don't have a need for transactionality (where all changes update or none do), and we do have a need to determine where this piece of data goes so we can dynamically compose a single mutation request based on whatever parts are present in the step. (corresponds with graphql mutation node this piece of data goes inside)
Key Principles, Other Details #
Once you've looked over the excessive lists and illustrations above, the following pieces of advice will hopefully make much more sense.
Use the smallest data surface you can with the highest benefit. You don't have to build your 'map' like ours, at all. Your data structure should be designed according to the layers of variance you need to go with. If you can use the presence of a piece of data to infer something else, do that. Where possible, have your code enforce sensible defaults, and make additions opt-in.
Example: we had three separate backend systems we needed to move data into/out of. The main one, a content management system, and an email communications system. Most of the data was written to/comes from the 'main' one, so we made that the default inputType. If a part was updating info in our cms, it could then declare that as it's inputType.
This is not completely hard and fast. Weigh what you add against the benefit you get. As you iterate, variance and functionality you require should work their way into the declared data.
Keep functionality in code until you have to move it into your declarative data.
We realized quickly there was a dependency graph between different parts of the wizard in different contexts (in this flow, we need a budget first. In this other flow, there is no budget). Hardcoding these requirements made the otherwise functional component code balloon, fast. Understanding what was happening turned implicit in confusing ways.
This led to the first major addition we made to our "parts," which was adding supplemental. This was a way for a part to request another piece of data from the greater context of the whole wizard. This also let us cleanly accomodate variance for different circumstances in different flows on top of the same set of components.
All parts have three modes: editing, editing[readonly], and viewing. No matter what your PO or PM tells you, this will happen: you'll need to display read-only versions of your inputs while requests are outgoing, and you'll need to display your data in different ways than you enter it the moment ux gets involved.
Do what makes sense. Not what you've done. One of the surprising areas to me was now that we could flexibly place and shape any part of the wizard flow into what made sense for the user, we didn't. There was resistance to this notion (initially).
Is there any reason to make someone click through 6 steps when only three pieces of data are editable and having the rest available for reference is what they need to get the job done?
Prefer functional composition along the seams of your variance... This one's hard to describe, but easy to demonstrate.
Do steps each need the full data of the wizard? No! They only need the minimum amount defined by their parts. Do parts need the full data of the wizard? Again - no! They need the bare minimum they define. Being able to have parts declaratively self-register into different pieces of information from the greater context lets you stay functional. It's important this opt-in capability doesn't pierce your layers of variance, or else things get messy.
For example, one of the most important functions in our implementation is named optionsForPart, and it consumes a wide variety of context to produce a clean, simple list of arguments each functional component consumes to render out the correct dom.
This function has our layers of variance baked in - it has no awareness of the greater map (statuses OR specific steps), only the specific place it exists (the part & any step actor). It knows how to consume a declared definition of a part, the surrounding context of the wizard, and this is where we can insert/enforce useful conventions (providing defaults for things, allowing for opt-in functionality, etc).
But take care of all other imperative operations via message-sending. We map out all the states we could end up in up front. Then, for more imperative areas of the system, we translate those into series of events that arrive as messages, and then are processed functionally. Promises emit loading, success, failure. User inputs fire off events.
This may or may not seem as standard advice to you, but it makes debugging so much easier.
Smaller details:
- Make everything serializable. This data structure probably eventually ends up in a mutable data store with an interface on top of it. This means those validation functions shouldn't get anywhere close to being
eval'd. - In js, it's extremely useful to store pieces of data as strings and then look those up out of objects (aka hashmaps). This lets you swap out implementations
- Don't bother with progressive save unless you've got great ux letting users know when saves have happened, and great conventions around promise management.
- We used
displayStateinside a step as a state bucket. This was the catch-all place - you could put whatever you wanted in here in a use-at-own-risk capacity. Starting with hairiness in here allowed us to harvest clean conventions and abstractions out of it. Provide some kind of mechanism that's amendable to iteration.
Final consideration is, we only had a need for straightforward wizard flows representable as lists. If you need branching structures, consider storing your steps inside a particular status as as a graph and building conventions around how "ADVANCE" or "PREVIOUS" work as well as the greater affordances.
Stepper States #
Something that's easy to miss scope around are "steppers," or the little bubbles that tell you where you're at. By instantiating actors for each step, and having those communicate their status to the wizard actor, it's possible to have each stepper become fully interactive. There are a couple dimensions that can influence UX, depending what you wanna do:
- visisted/unvisited
- complete/incomplete
- valid/invalid
- whether step the stepper represents is: before current step, is current step, is future step
I'd suggest visited/unvisited probably isn't worth that much, but the entire exercise is competing priorities anyway. For example, complete/incomplete could easily be argued to be the same thing as valid/invalid, but... what if the step is largely optional? You might want to convey "this has been filled out" vs "this hasn't been."
Here's a brief example of one approach:
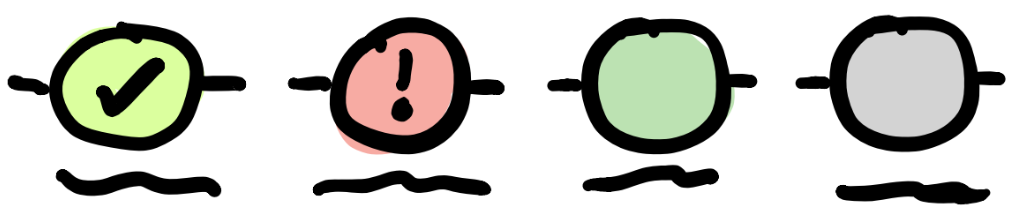
- valid/invalid are connoted via green check, or red !
- hierarchy emphasizes the bubbles and color over the name of the step, valuing "where you are in the whole flow" over "where you are right now"
- previous to current step has higher opacity
- further than current step is greyed out
- current step is least opaque color
What this would look like in practice is:
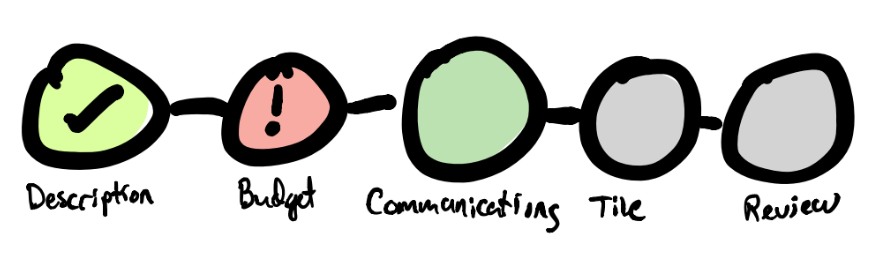
This design conflates validity with complete/incomplete.
Some different ways you could approach this are:
- let color represent valid/invalid
- let circle border or some other affordance represent previous/current/next
- let icon inside represent complete/incomplete
- let some other affordance represent visited (a purpled name link)
Architectural Questions #
Here are they key questions to think through:
- What kinds of variance will I need to deal with? (phase, kind, circumstance)
- What kinds of change requests does this part of the system get most often?
- Where does this wizard fall on the one-time <-> power user spectrum?
- Do I want interactive steppers? Do I want to hide progress entirely?
- Do I want to offer crud-like management of wizard flows at some point in the future?
This post probably has too much in it. I might break it up into a smaller series of posts, based on feedback. If you'd like help thinking through your situation and this post doesn't cut it for you, drop me a line @zemptime
Possible TODOs:
- [ ] convert png to jpg
- [ ] restructure to call out spa/server rendered concerns visually separate
- [ ] walk through graphql design