Why Two-Way Data Binding Is(n't) Bad
Recently, at a javascript meetup in St. Louis, one question rippled through the entire evening. This caused two things to happen, which usually don't:
- Nearly every party in the room gave an impassioned perspective, in a decidedly un-midwestern (and fun) departure from the normally serene meetups, and
- Everybody had a different answer to the question.
Why did this question cause passionate outbursts? And then... why did everyone answer differently?
Is two-way data-binding bad?
Two-way data binding? #
Just to be clear, this is probably exactly what you think it is.
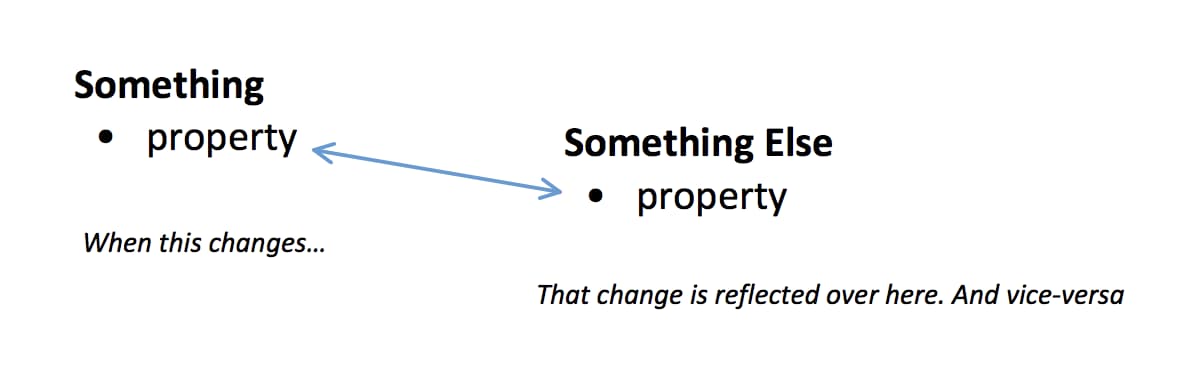
One reason so many different people spoke up is because data-flow is something everybody has to deal with. In the beginning, the two-way approach was present across the gambit of available frontend frameworks/libraries - Angular 1.x, Polymer .5/1, (now Vue.js sort of), etc. Then React came along with Unidirectional data-flow, the Flux pattern began getting heavy adoption, and boom. Everything shifted. Context set. Now, for the interesting stuff:
When somebody tells me what they think about two-way data-binding, I can immediately begin making good guesses about what kind of environments they've coded in.
- How long a given group of developers operates on a given codebase
- The quality of those developers
- The complexity of the domain
With a little more data (how big the business, what business, what library/framework), I can usually piece the rest of the story together and make surprisingly accurate assumptions about what their day-to-day life was like, as though I was some sort of fly on the wall. This is because the environment they were in then is what built the feelings they're speaking to me now.
Two way data binding isn’t bad because two way data binding is bad. Some people don’t like two way data binding because what it does is, every time you use it, is create an implicit link in your codebase. And it's really the properties of implicit knowledge that affect how the three factors that mix together: 1) the size/retention of your team, 2) the quality of your team, and 3) the complexity of your domain.
Implicit Knowledge Tradeoffs #
Let's get this straight: code is just thought. It's thought, translated into written form, that has two audiences - programmers, and computers. Code is bits and pieces of the real world selected by programmers, and translated into a format in which a computer can understand it.
So working with code means working with people. And working with people means you're working inside some constraints. And it's these constraints that determine if implicit knowledge is a good or bad thing in your code base. The main constraint on a given programmer, is the amount of things they can hold in their head at a given time.
There comes a tipping point in any codebase, where the level of implicit knowledge required exceeds what someone can reasonably hold in their head and the cost of change skyrockets. It doesn’t usually do this for the person who wrote the stuff, but everyone around them (because the person who wrote it has the implicit knowledge).
(Incidentally, in big-co settings, this is why it's good to measure performance of individuals by the output of their entire team - otherwise you could have one 'star' coder who's shipping a ton, looks great, and it seems like everybody else is slow. What's really happening is that one person is behaving in a way that optimizes them for the short-term, but adds tons of blockage and added cost to everything downstream. This is structurally setting up everyone else to fail, and if they leave, you're screwed.)
So, here are some key scenarios:
- You can have a codebase that gets worked on by a highly rotating team. In this case, two-way db is a bad fit
- You can have an incredibly complex codebase maintained by really skilled coders, and be totally fine with 2-way db
- You can also have a simple codebase that’s incredibly complex because your coders fudged it up
Two-way data binding means key information lives in your head instead of inside the code. It takes less time to write.
You can have a small, skilled, enduring team working on the same codebase over a long period of time, and implicit knowledge is a great fit here. It's because that implicit knowledge gets loaded up into all the coder's heads, and there's less ceremony between what they think, and that thought becoming code. So in this context, implicit knowledge (two-way db) is potentially better than explicit knowledge (unidirectional data flow) because it lets you move faster.
Trigger Warning: what I say next will probably make some of you angry, turn you off, and think, this guy's an idiot! But here it is: with consistent and skilled coders, this actually makes explicit approaches (ex: using Redux) a potential roof on how fast you can move.
Implicit knowledge isn’t a bad thing. In fact, it might be faster than strict unidirectional flow. But what happens, the reason why people don’t like it, is because what it does is introduce the capacity to even have continually increasing complexity over time. Those of you who shuddered in revulsion at my suggestion of not using Redux, you've suffered what I'm about to talk about:
Two-way data binding hell #
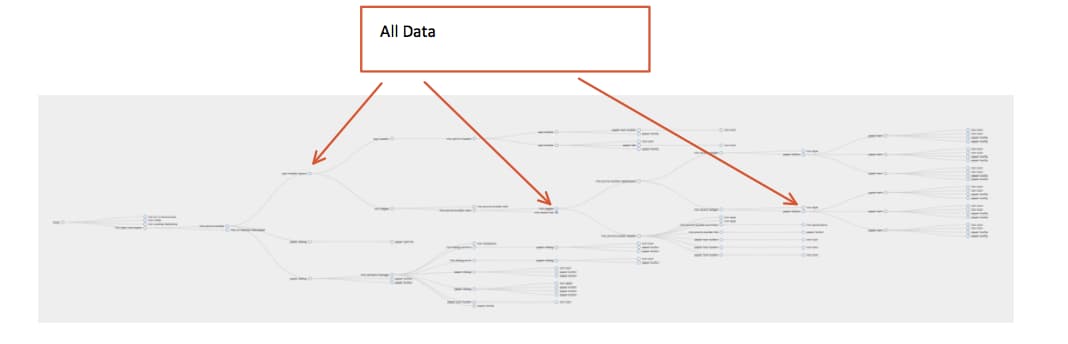
There is a huge downside to two-way databinding, or implicit knowledge, if used improperly. Let's take a look at the graph visualization of a page middling complexity. (It's blurry on purpose - you can imagine this as a visualization of Angular Components, Web Components, etc).
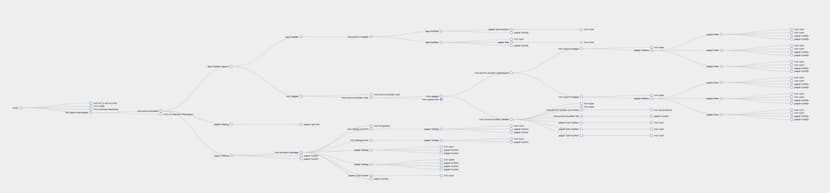
And, let's focus in further, on a node in the middle. What we're going to investigate here is the measurement of cyclomatic complexity - a quantitative measure of the number of linearly independent paths through a program's source code.
In order to understand what kind of information is present here, we'll measure the amount of places that could potentially affect what's in there.
- Properties passed down from components further up the tree
- Events passed up from further down the object tree
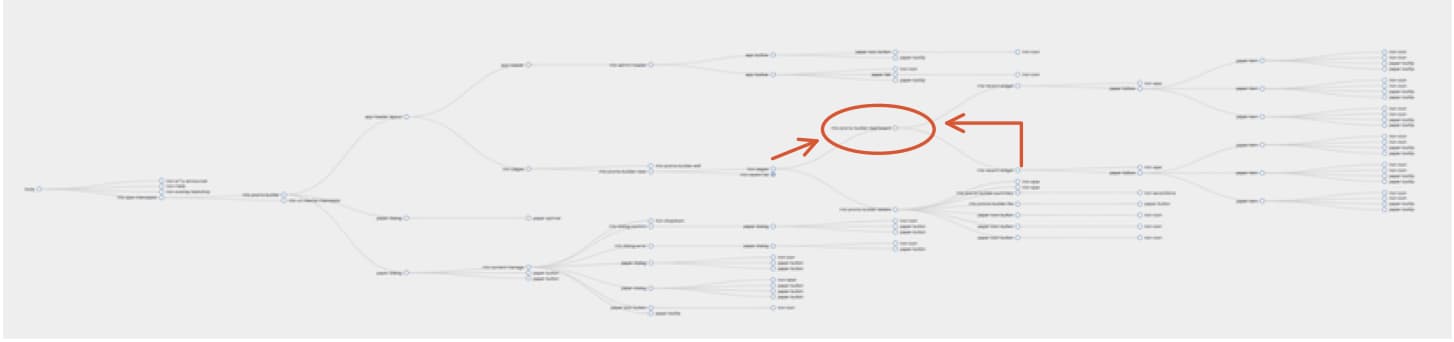
So you might think, the cyclomatic complexity of determining the state of our target node is 2. Except, in this case, before state is received by the node we're focused on, it's passed through ~7 other nodes. And then it has 36 children who could potentially dispatch events which could modify it. So, hopefully it's two, but it's worth considering the impact these other nodes could have because...
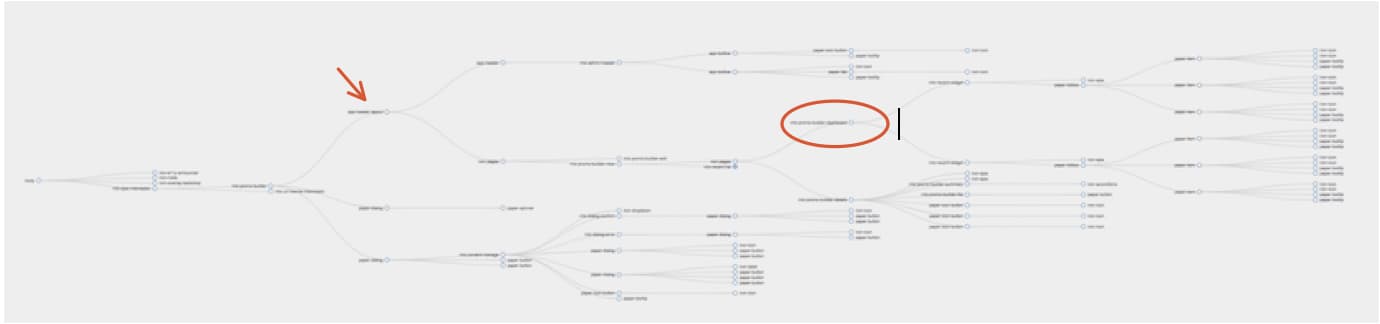
This one determines a really important piece of state: a selection who's value changes a good deal of values elsewhere. Here are examples of this:
- A form on a wizard that modifies what later steps present
- A scheduling selection - weekly, monthly, yearly, etc
- A different kind of account, resulting in a bunch of different processes needed
So what's set up there can have an impact on how our node needs to behave. Since that piece of data over there might materially change how we need to behave over in our original area, you have to take the state of that into account when coding. And to understand that piece of data, you go through the same process - what properties are passed to it? What events modify it?
In order to safely introduce a desired change, two way data binding sets up the potential structure where you quickly approach needing to understand the entirety of everything on the page in order to safely change one specific area.
You can't really do a big o analysis of this because it depends on your exact setup, but in general I'd characterize it as: potentially up to properties^nodes.
This is when making a seemingly simple change to a page takes two days and tons of things break. This is when you start churning developers, velocity slows down, and things get bad. This is two-way data binding hell. And it creeps up on you, slowly, over time, because at the start everything is actually faster.
Unidirectional Data Flow #
The alternative is unidirectional data flow. Remember, the constraint we can't move around is that people work on the system. And people are limited by the number of things they can hold in their head.
Specifically here, I'm going to talk about: vanilla two-way data binding vs adopting a single-store based approach like Redux.
- Two-way data binding: introduces a potential roof on complexity of (properties^nodes)
- Unidirectional data flow: ???
Instead of needing to track state over time, you have one single representation. Then, when you need to modify state:

You dispatch an event that will trigger the mutation you want inside this single representation.
The singular benefit of doing this is it puts a roof on the potential complexity of the number of things you need to hold your head. In order to safely introduce a change, you need to understand
- old state + action = new state
The amount of pieces of information you have to hold in your head is safely reduced to/capped at: 2.
- Two-way data binding: introduces a potential roof on complexity of (properties^nodes)
- Unidirectional data flow: 2
Tradeoffs #
The whole discussion of two-way data binding being bad or not boils down to:
- Implicit vs Explicit Knowledge
- Optimize for # of things people have to hold in their heads to introduce change
And these factors squarely depend on:
- How long a given group of developers operates on a given codebase
- The quality of those developers
- The complexity of the domain
This is why everybody answered differently. And this is why asking if a practice is "good" or "bad" without context can lead to decisions being made without considering important information that, had the people making it known, would've changed what they decided.
So my final ask/conclusion here is fairly conventional. When you're in the position of responsibility where you get to define how the UI portion of your organization is going to handle data flow, don't make a decision from your own personal pov. Make it from your organizational POV.
Other Great Links #
- Programming with a love of the implicit
- (more will be added I lost track)